KomgaBangumi 漫画服务元数据刮削器
KomgaBangumi
Komga 漫画服务器元数据刮削器,使用 Bangumi API,并支持自定义 Access Token
用于自建 Komga 服务刮削漫画元数据,生成 Metadata 和封面
脚本制作的由来
事实上目前已经有两个可以使用 Bangumi API 进行元数据刮削的 Komga 轮子了:BangumiKomga 和 komf,之所以制作此脚本是因为它们具有以下痛点:
-
BangumiKomga 对于单本漫画下的书籍强制重排序,由于用户文件命名场景的复杂性势必会导致破坏一些漫画的数据
-
不支持刮削 Bangumi 上的原名和别名信息
-
komf 无法从类似
[漫画名称][作者][出版社][卷数][其他1][其他2]的文件命名格式中正确提取漫画名用于匹配
因此基于 eeezae 的原始脚本 KomgaPatcher 修改并增加了各种功能后诞生了这个脚本(还有位协作者:ramu)
PS:komf 的实时监测和增量更新依旧很好用
功能
- 从 Bangumi API 获取系列和卷的元数据及封面
- 支持 bookof.moe 作为备用数据源 (刮削)
- 在 Komga 界面添加刮削按钮
- 批量精确匹配库中的系列
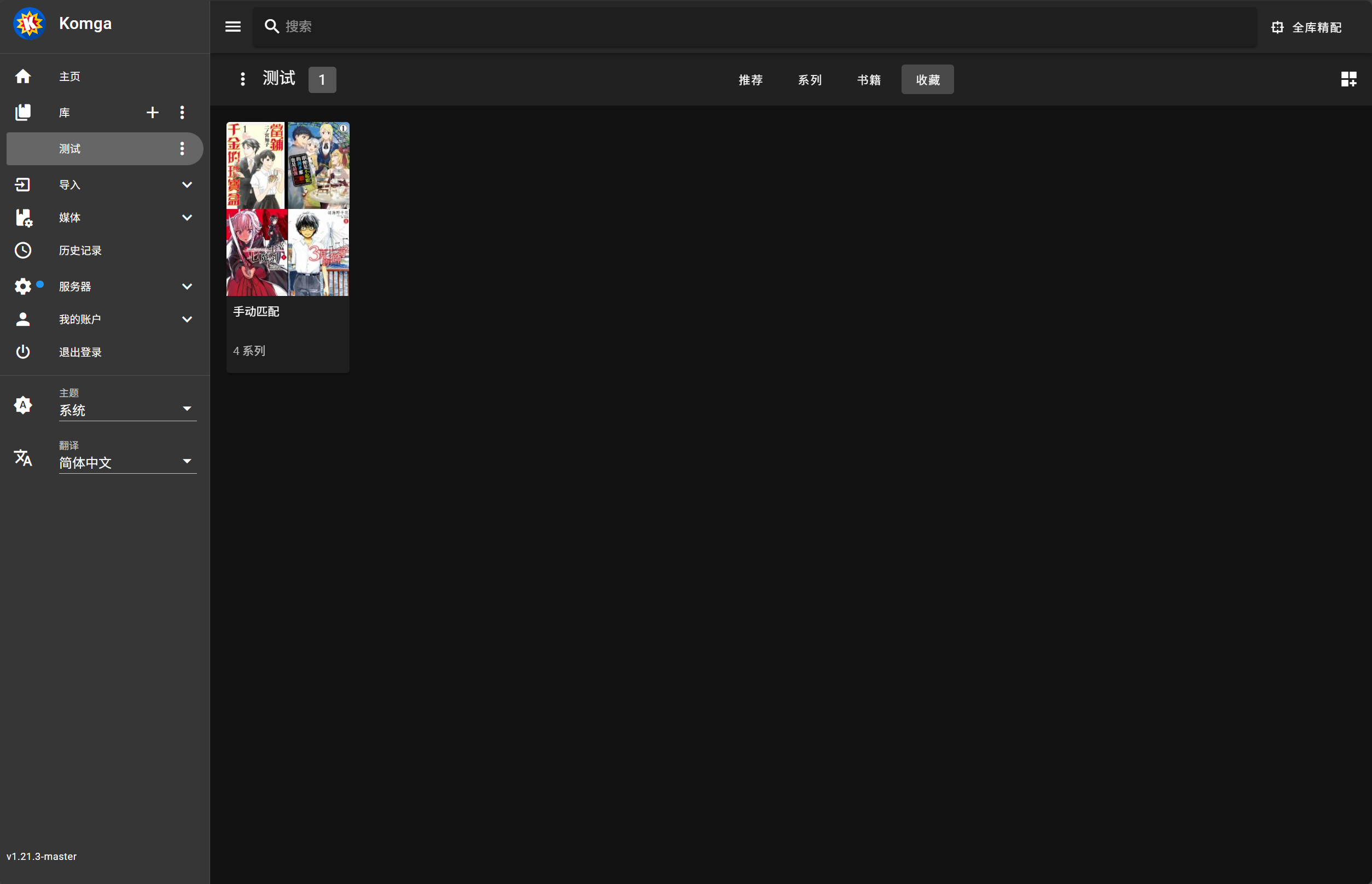
- 失败的系列自动添加到 “手动匹配” 收藏夹
- 允许用户通过油猴菜单配置 Bangumi Access Token
- 当 Access Token 失效 (API 返回 401) 时提示用户更新
安装
- 确保你已经安装了浏览器扩展 Tampermonkey (Chrome, Firefox, Edge, Safari 等均支持) 或兼容的用户脚本管理器
- 点击以下链接安装脚本:

说明
刮削按钮在每本书封面处下方,会生成两个圆形按钮,按钮是默认隐藏的,只有移动到书籍封面上才会显示,包括书库和书籍详情页都会生成
左侧按钮用于只刮削 Metadata 信息,右侧按钮用于刮削 Metadata 信息和所有封面
在库视图的顶部工具栏会添加 “全库精配” 按钮
支持的文件命名格式示例
本脚本支持从以下类似格式中自动提取漫画名:
漫画名[漫画名][作者][漫画名][出版社][卷数][漫画名][作者][出版社][卷数][其他信息]
仅漫画名字段会用于与 Bangumi 名称(含原名 / 别名)进行严格匹配
使用方法
-
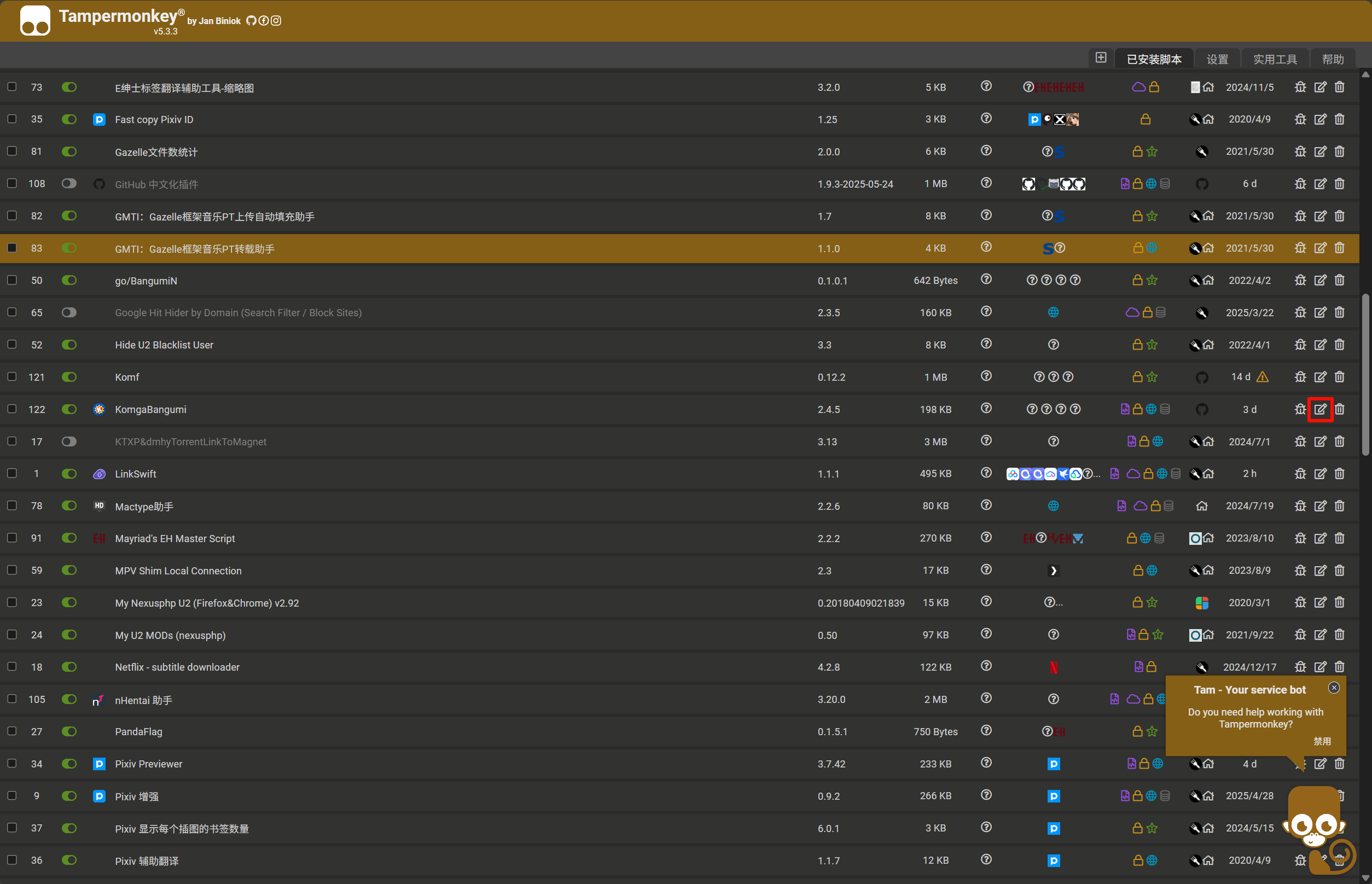
配置 Komga 服务域名或
ip:port地址用于脚本识别- 打开油猴 Tampermonkey 的管理面板(Dashboard)
- 找到 KomgaBangumi 脚本,点击编辑按钮(铅笔图标)
- 切换到 “设置” (Settings) 标签页
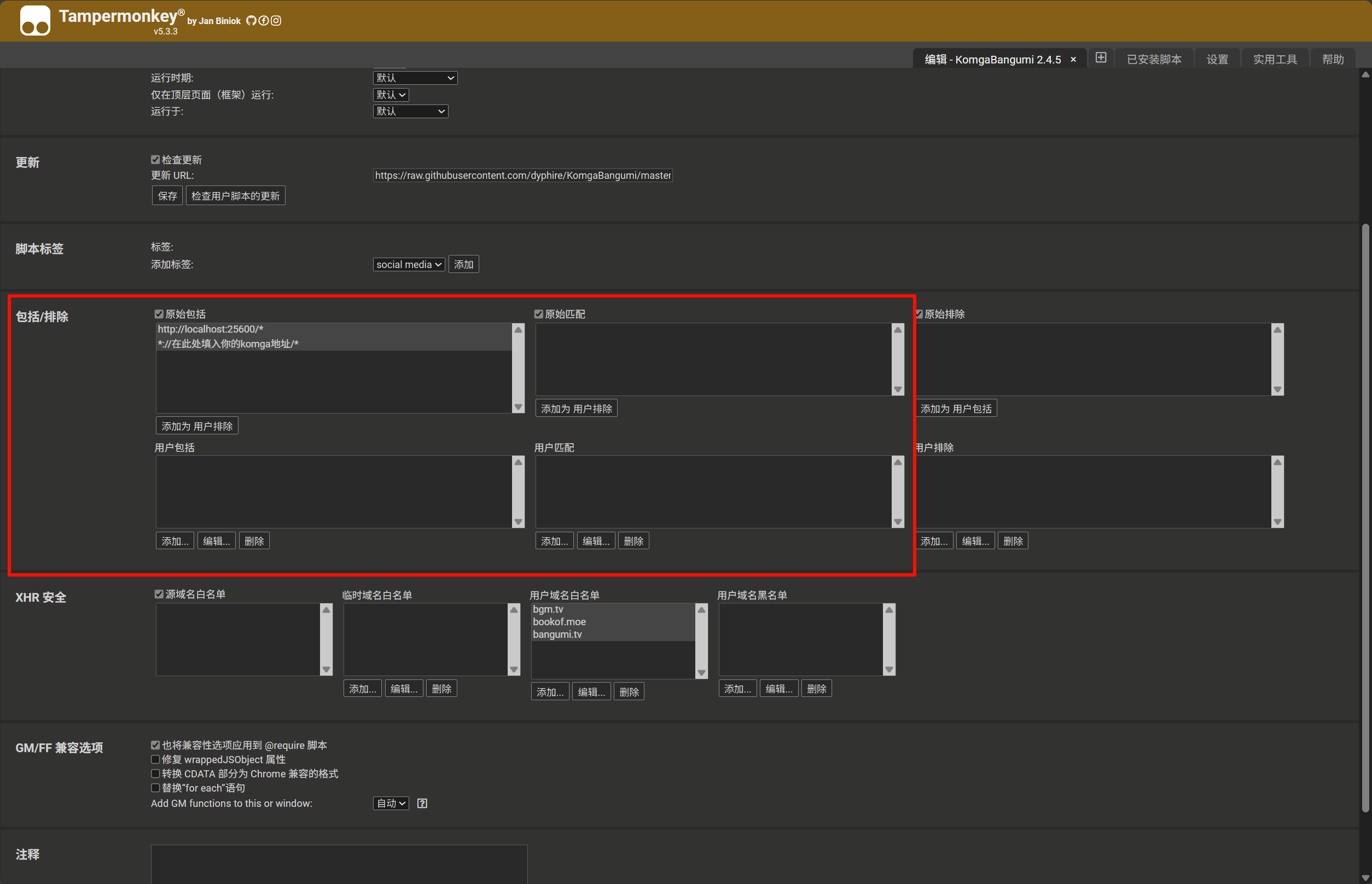
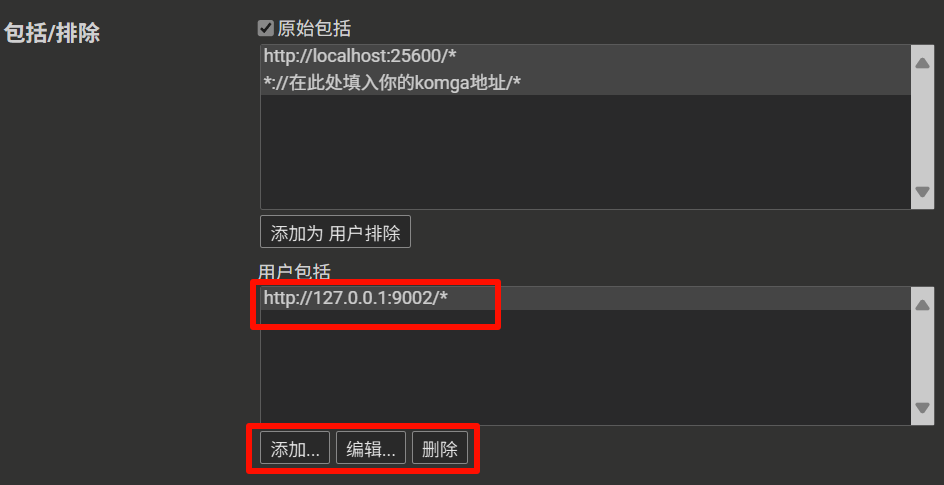
- 找到 "包括 / 排除 (Includes/Excludes)" 部分
- 在 "用户包括 (User includes)" 或 "用户匹配 (User matches)" 中添加您的 Komga 服务域名匹配规则,例如
https://komga.org/* - 保存设置
-
配置 Bangumi Access Token (可选,用于搜索 NSFW 条目)
- 在浏览器中访问你的 Komga 服务网址
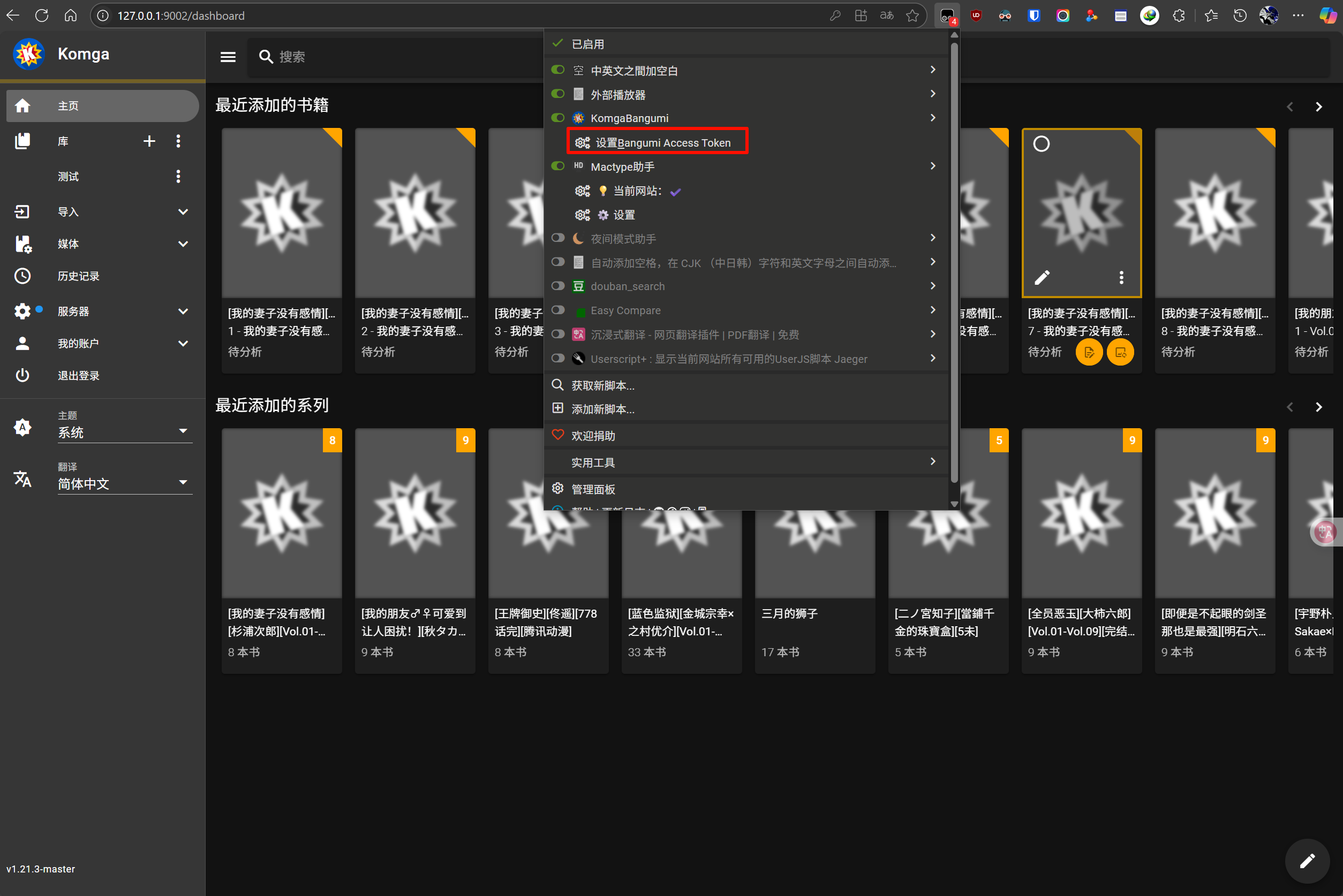
- 点击浏览器工具栏中的 Tampermonkey 图标
- 找到 KomgaBangumi 脚本
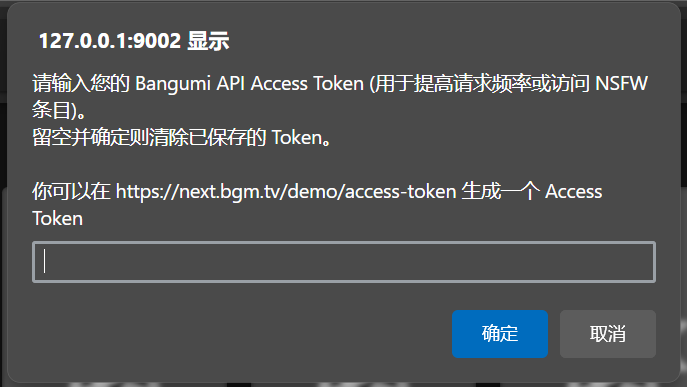
- 选择 “设置 Bangumi Access Token”
- 在弹出的对话框中输入您的 Token。留空则清除
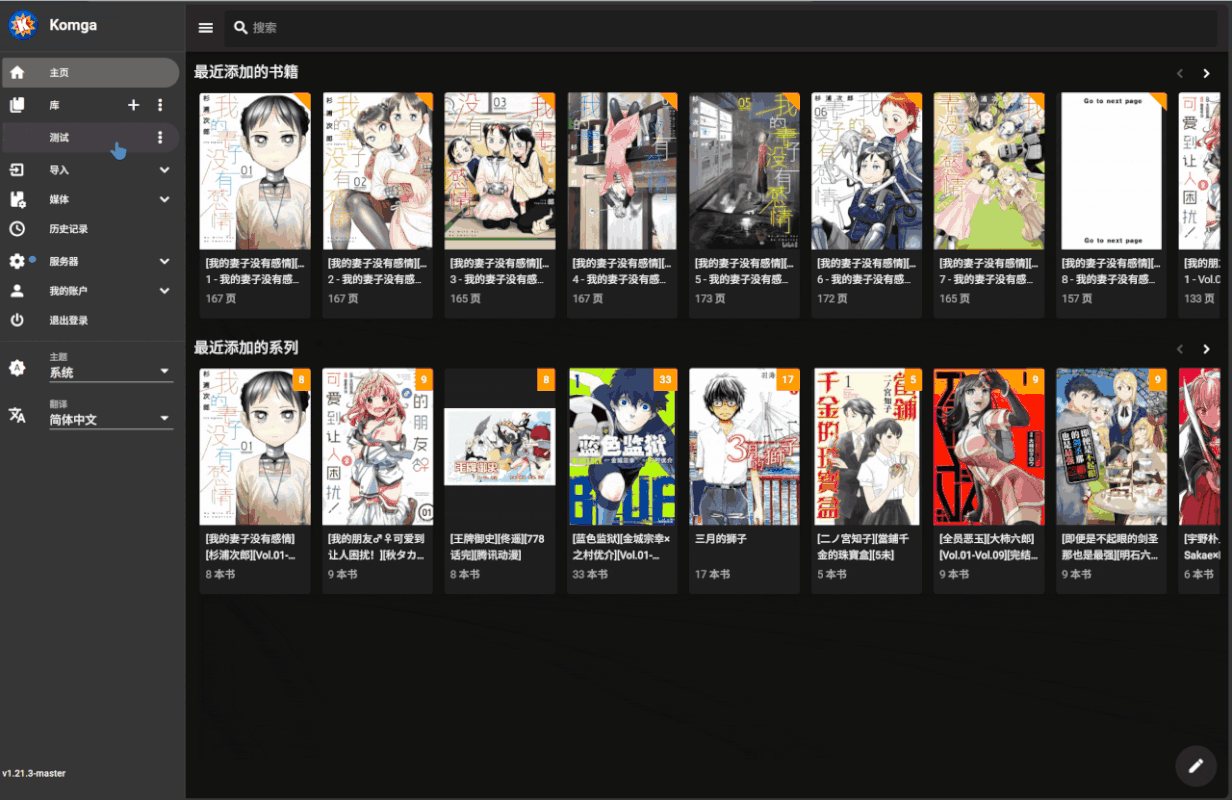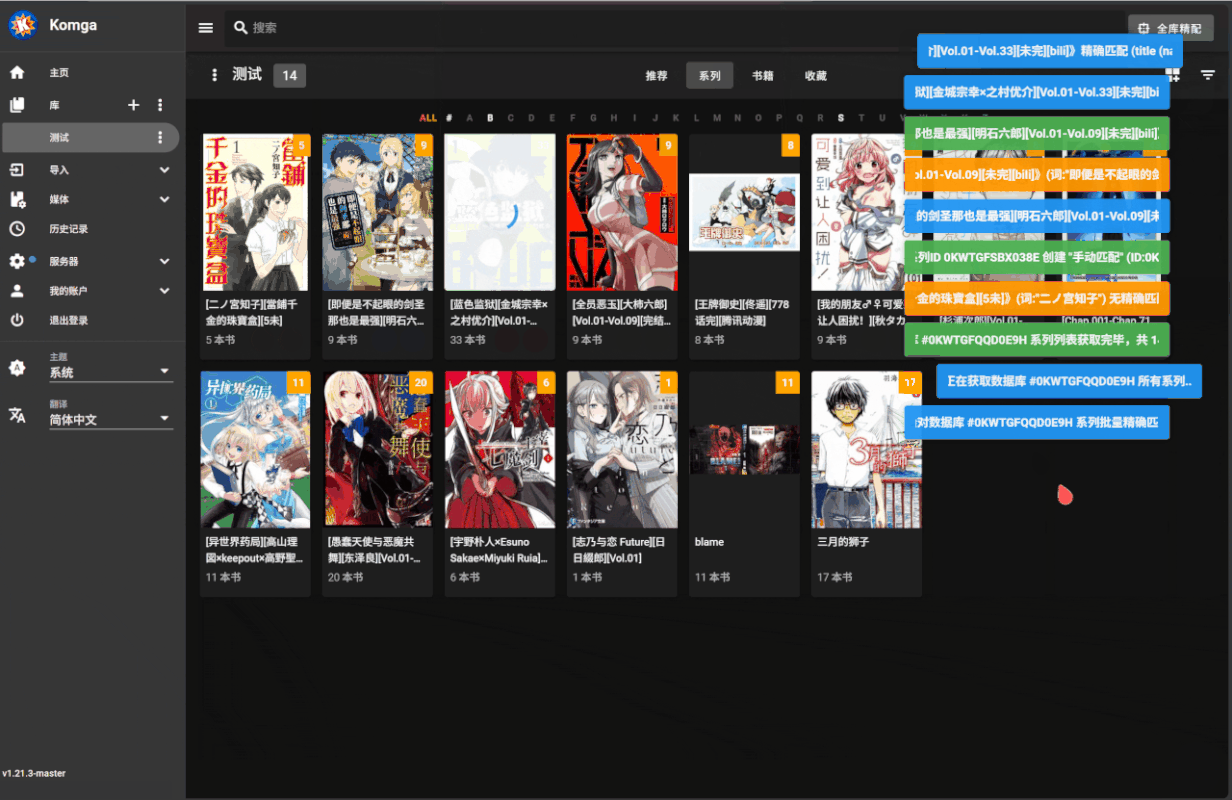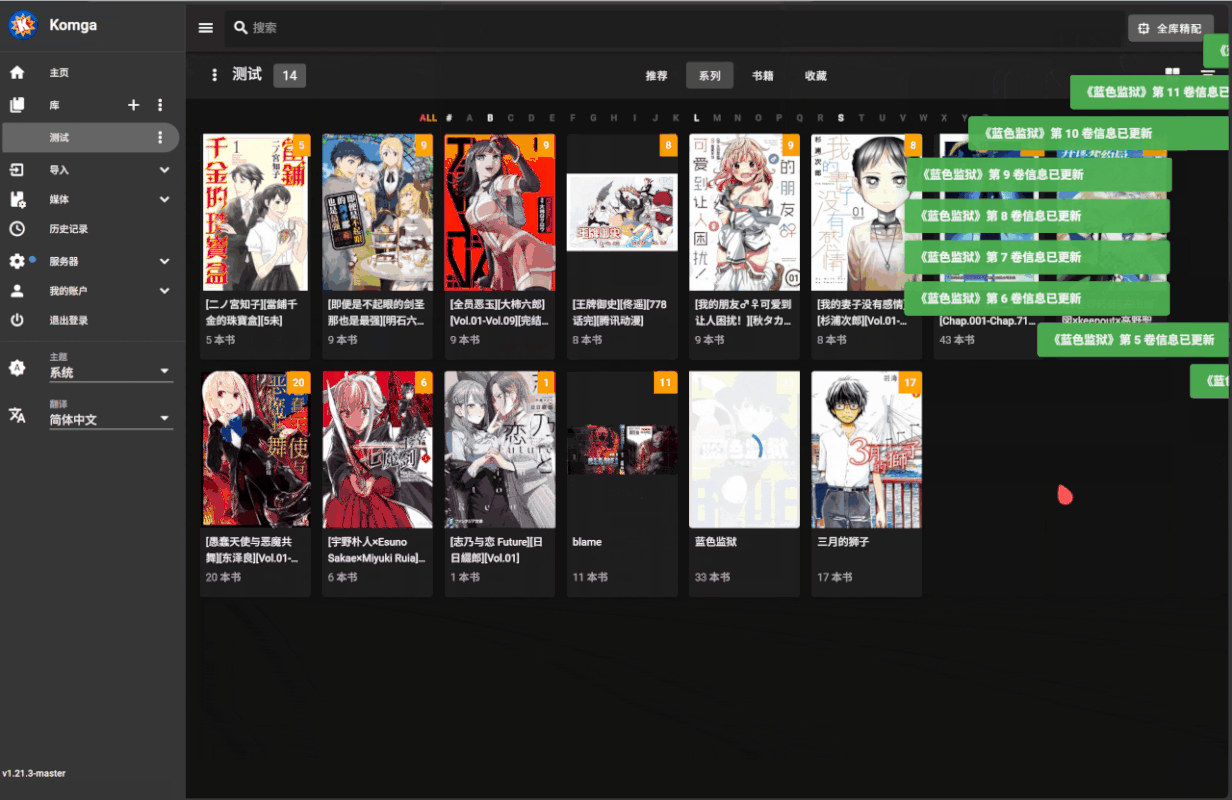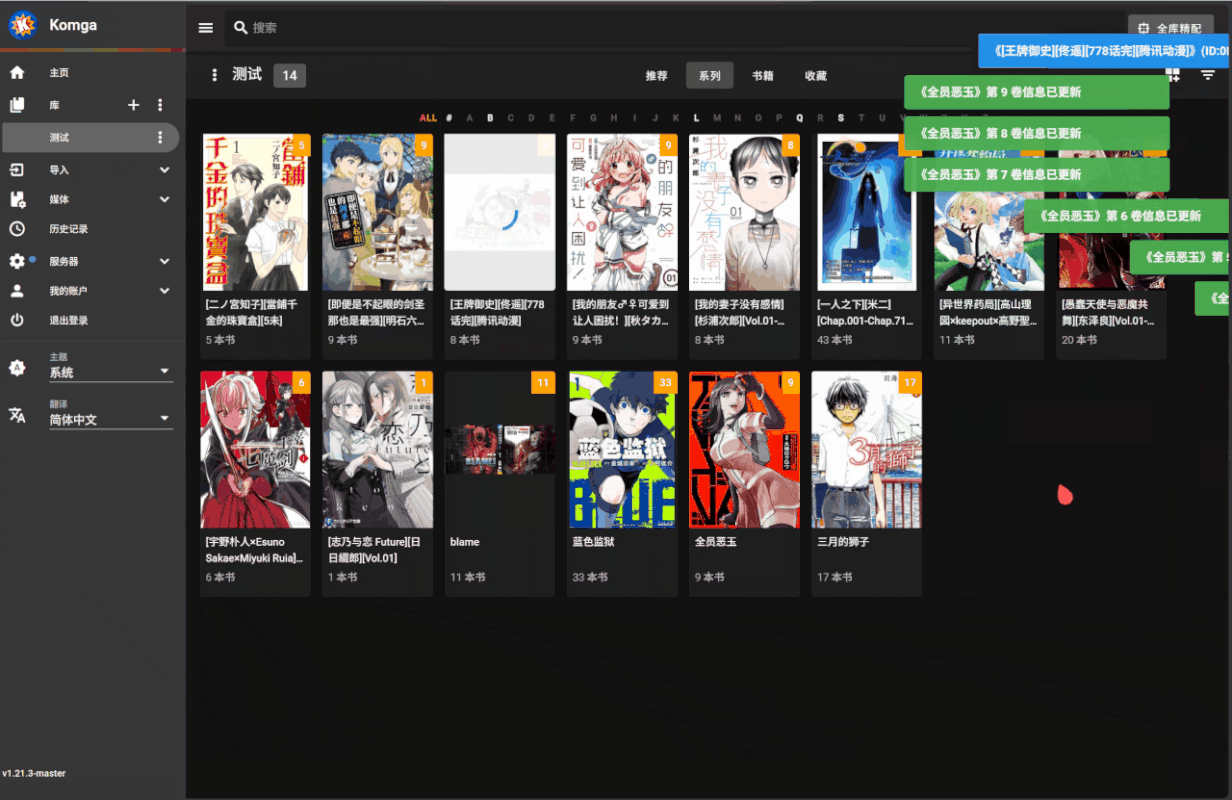
批量匹配操作
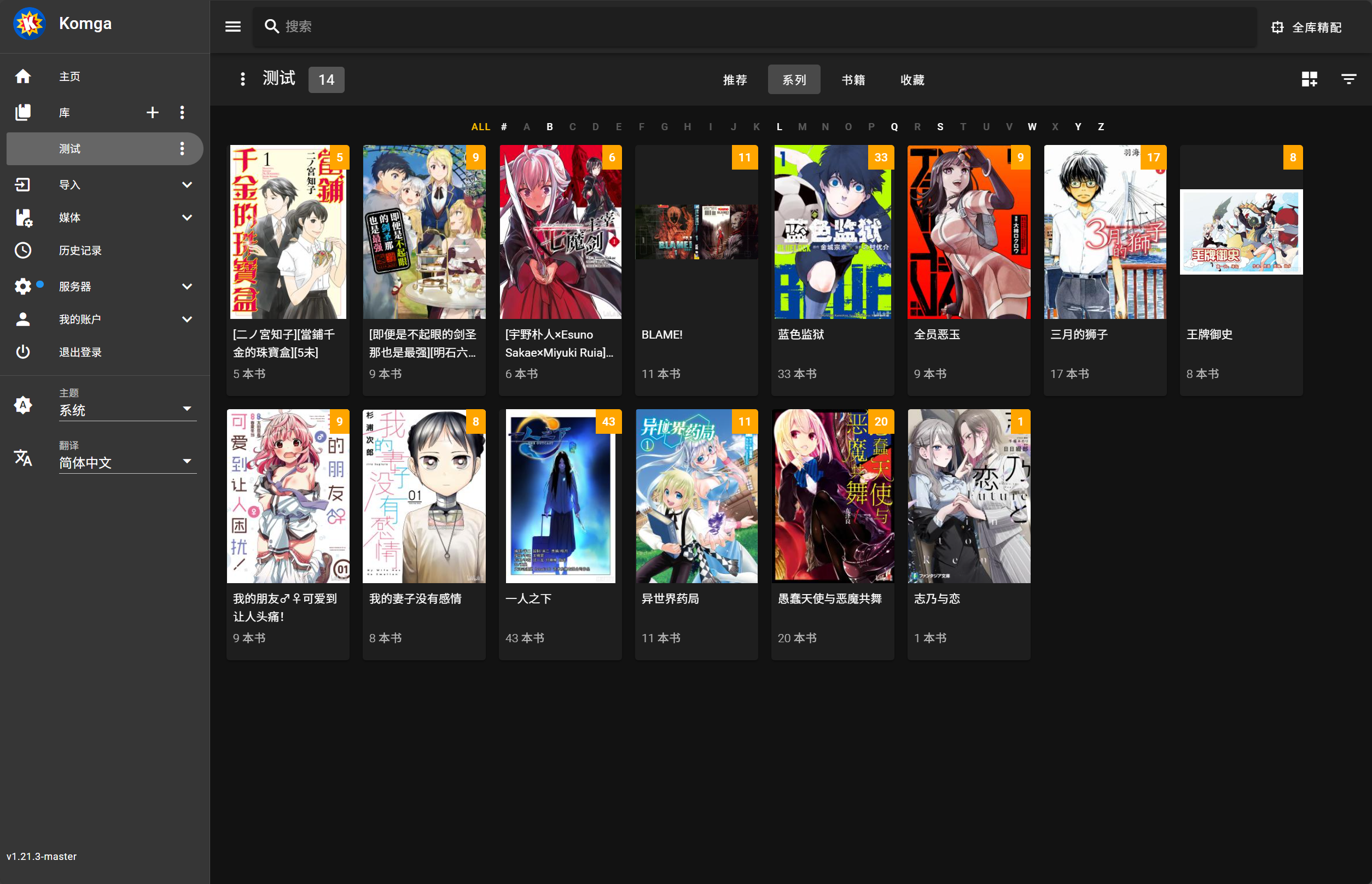
- 切换到想要执行批量匹配的库
- 点击搜索框旁边的全库精配按钮
- 确认后不要关闭页面等待脚本自动刮削完成(耗时由库里的漫画数量决定)
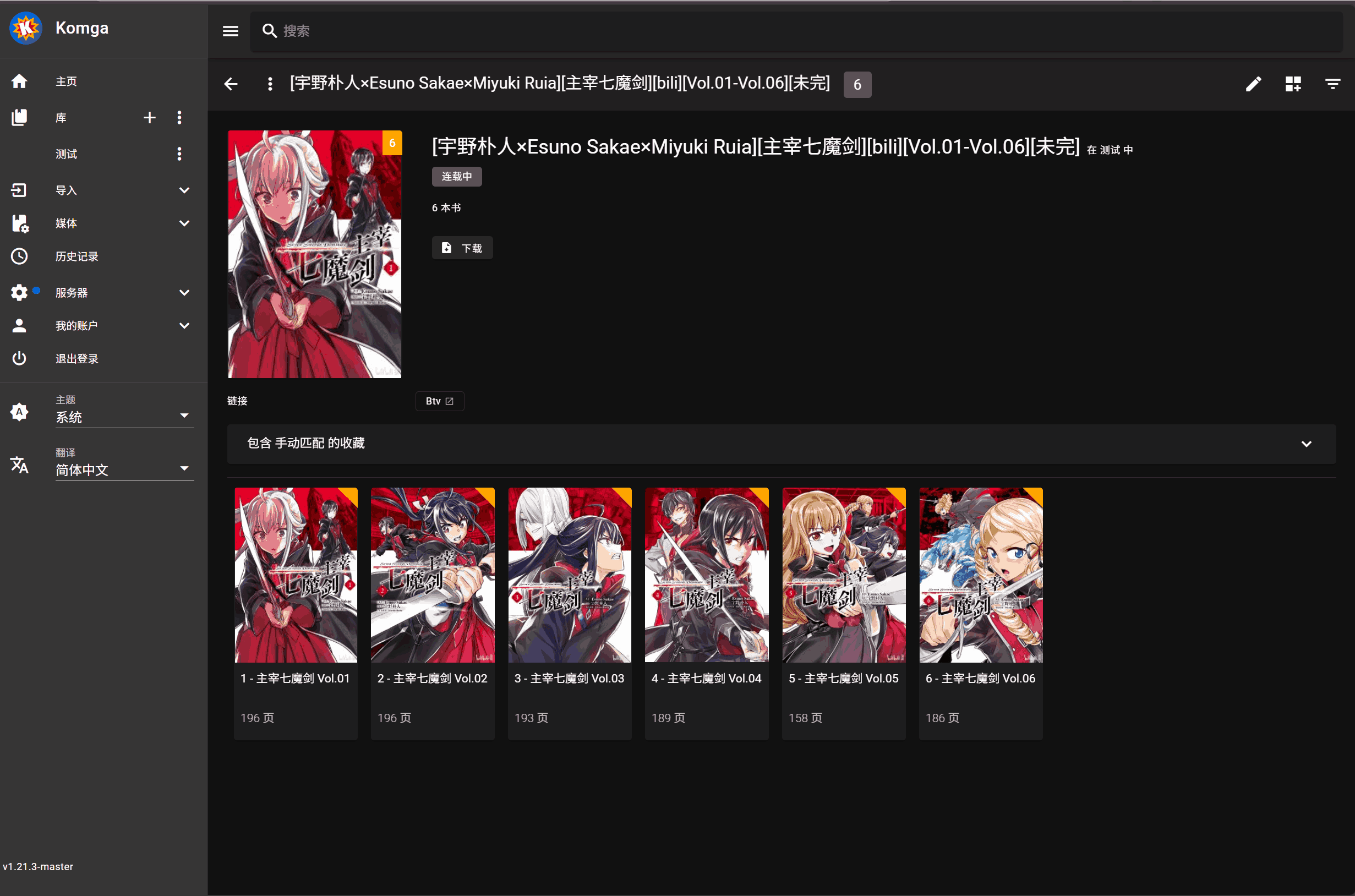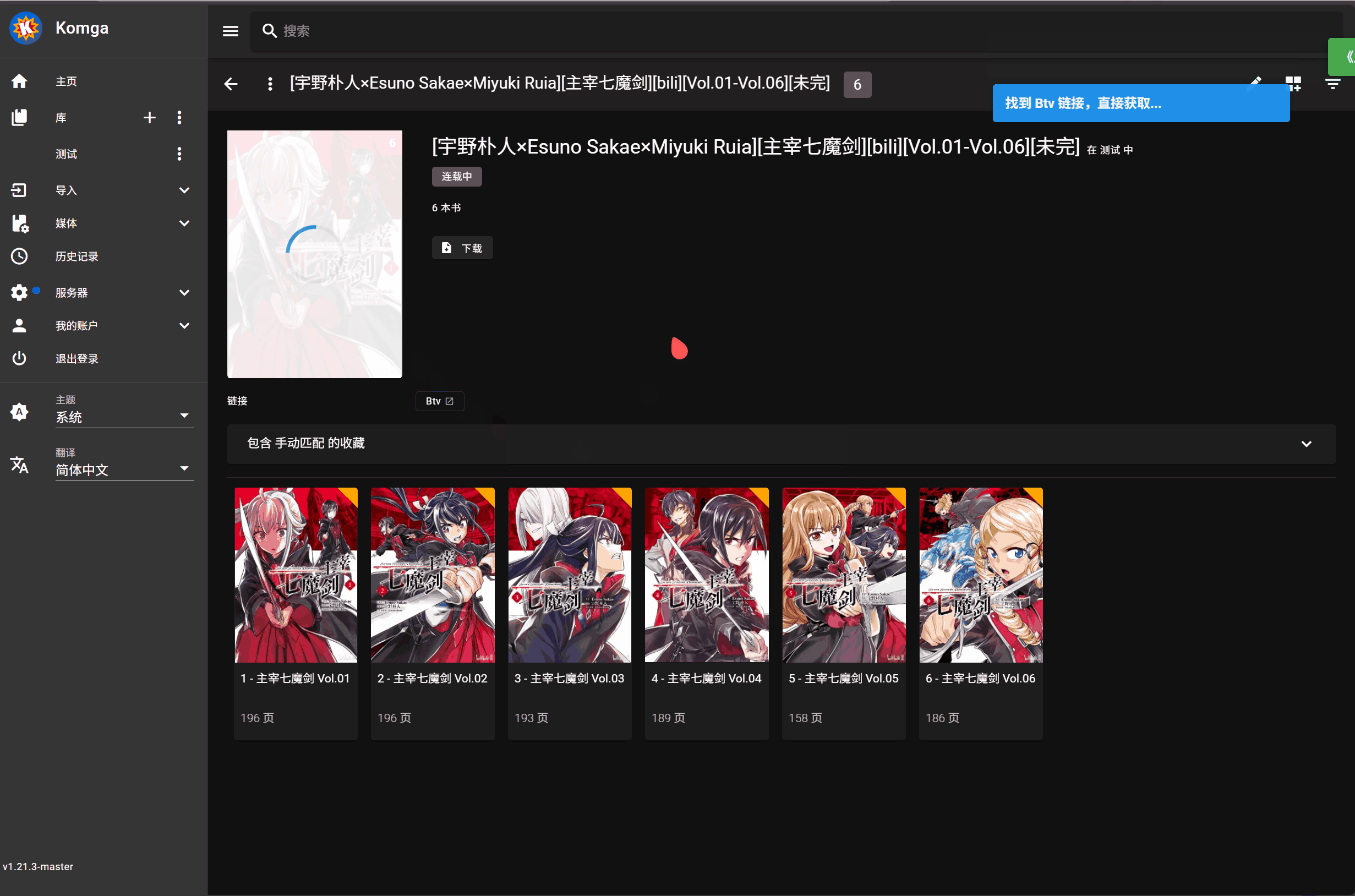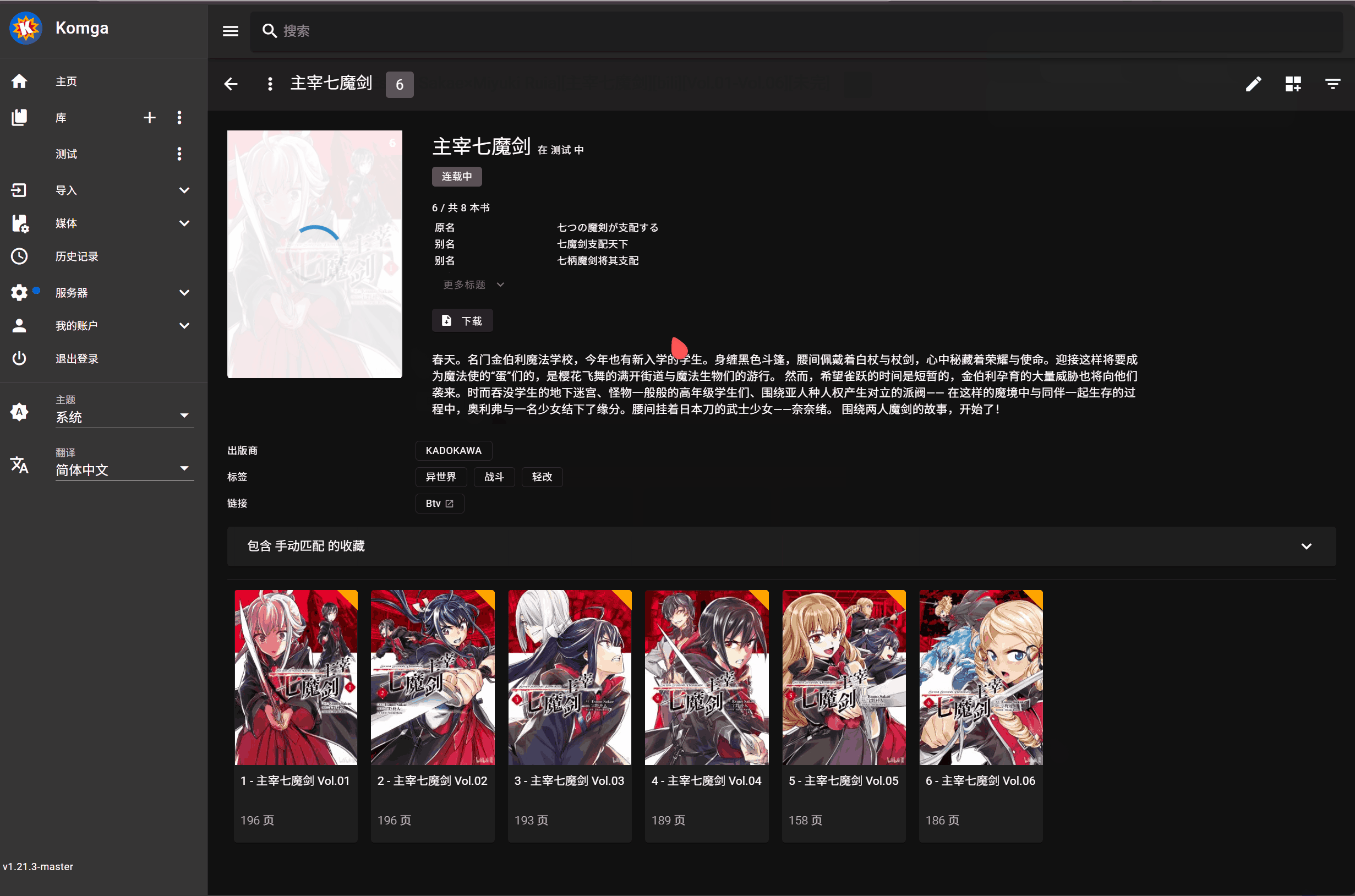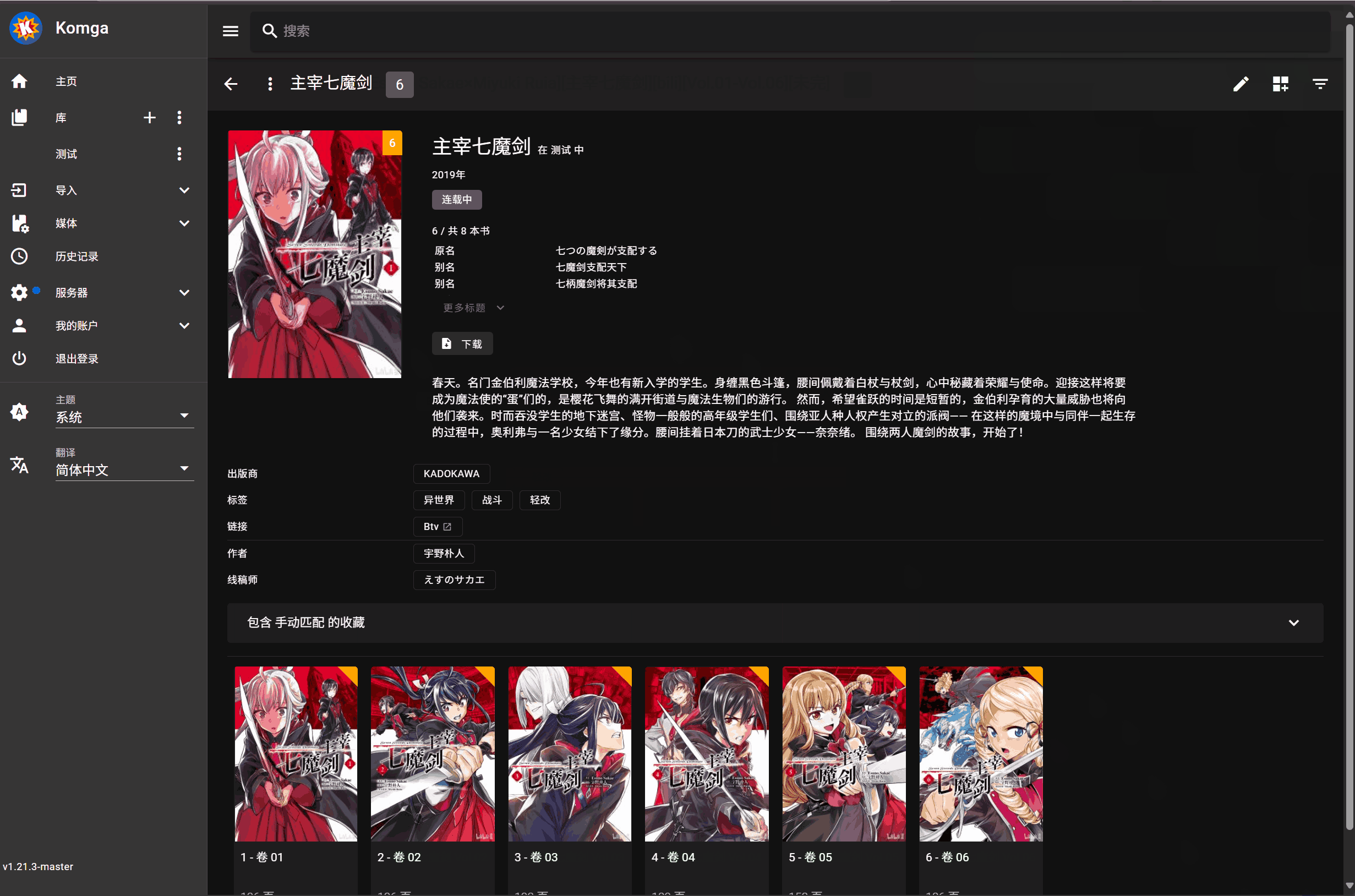
系列漫画元数据中已有
Btv链接信息的会被跳过,确保只进行增量匹配更新批量匹配逻辑会和 bangumi 上漫画的中文名、原名和别名进行匹配,只有名称完全一致时才会视为成功,不进行模糊匹配(防止误匹配
支持从类似
[漫画名称][作者][出版社][卷数][其他1][其他2]的文件命名格式中正确提取漫画名匹配失败的漫画系列会自动添加到名为 “手动匹配” 的收藏夹中
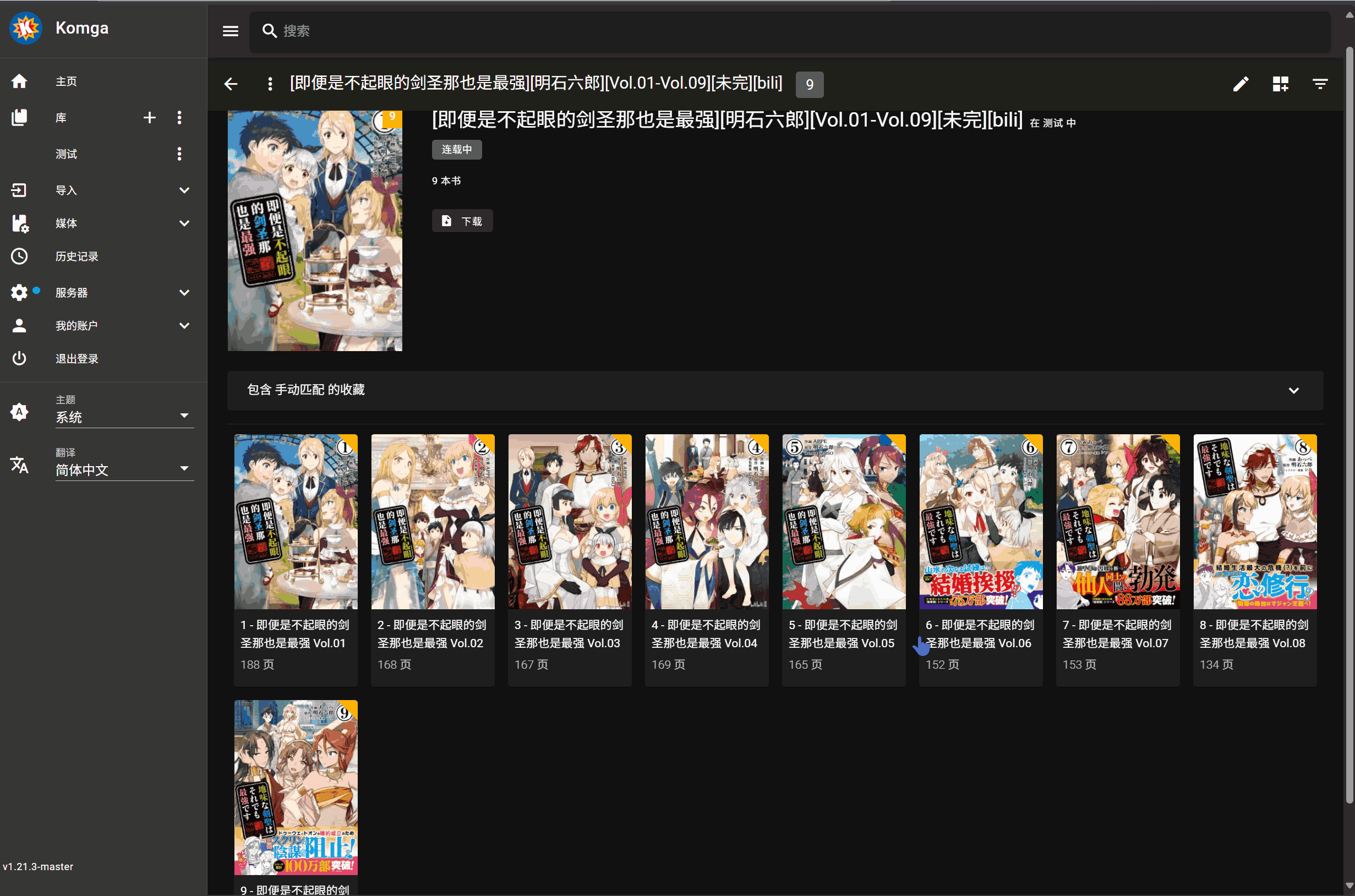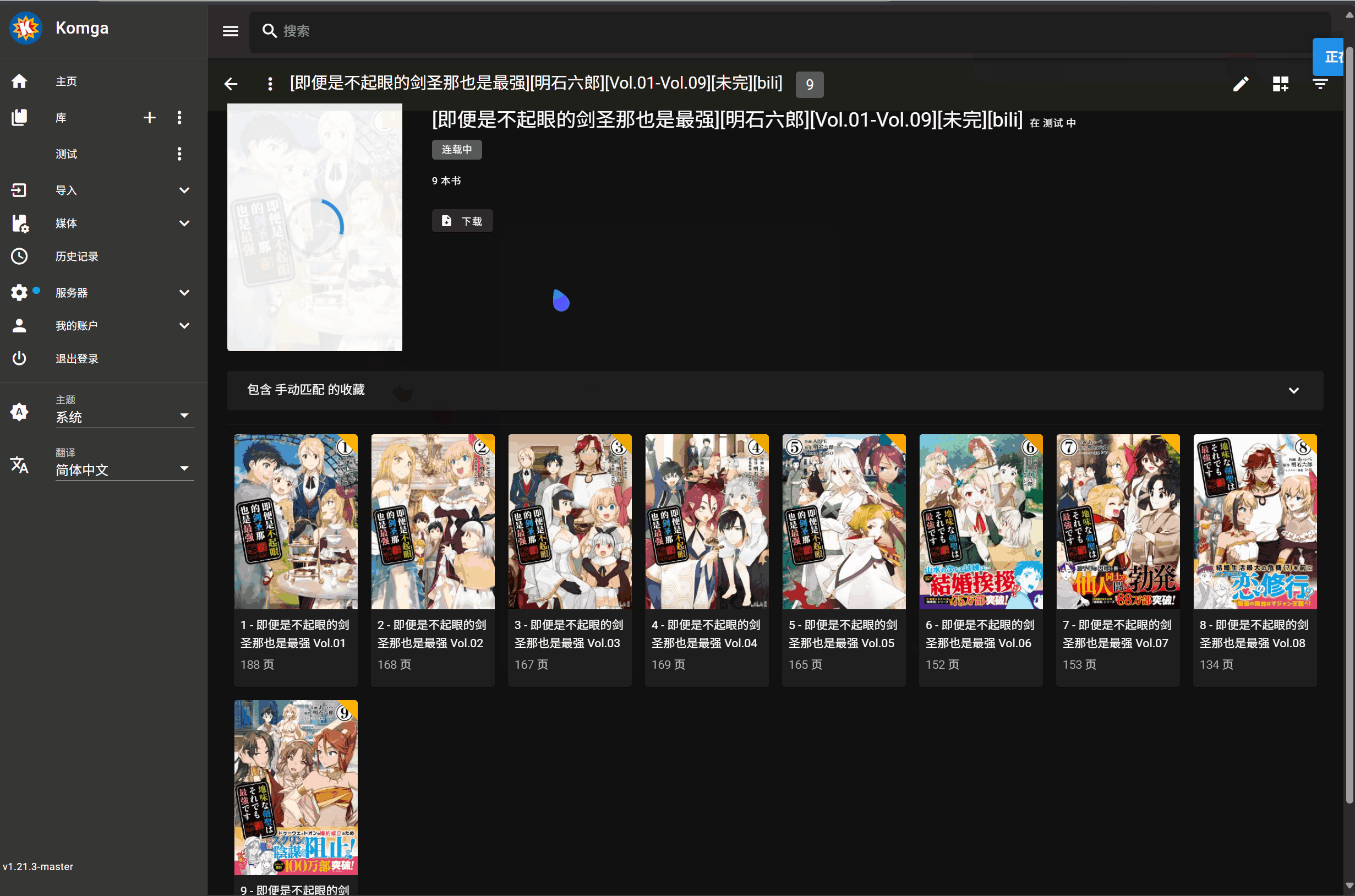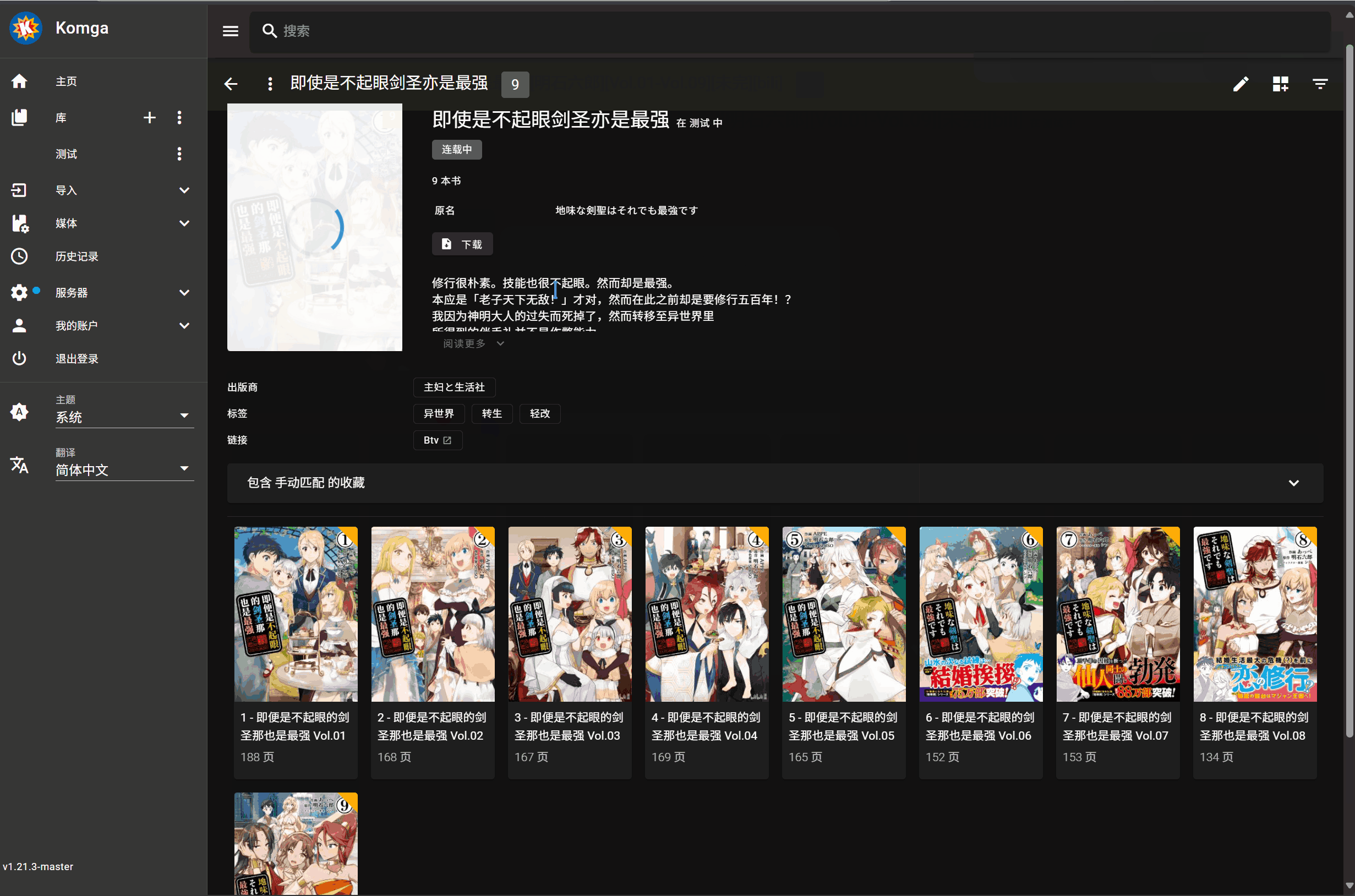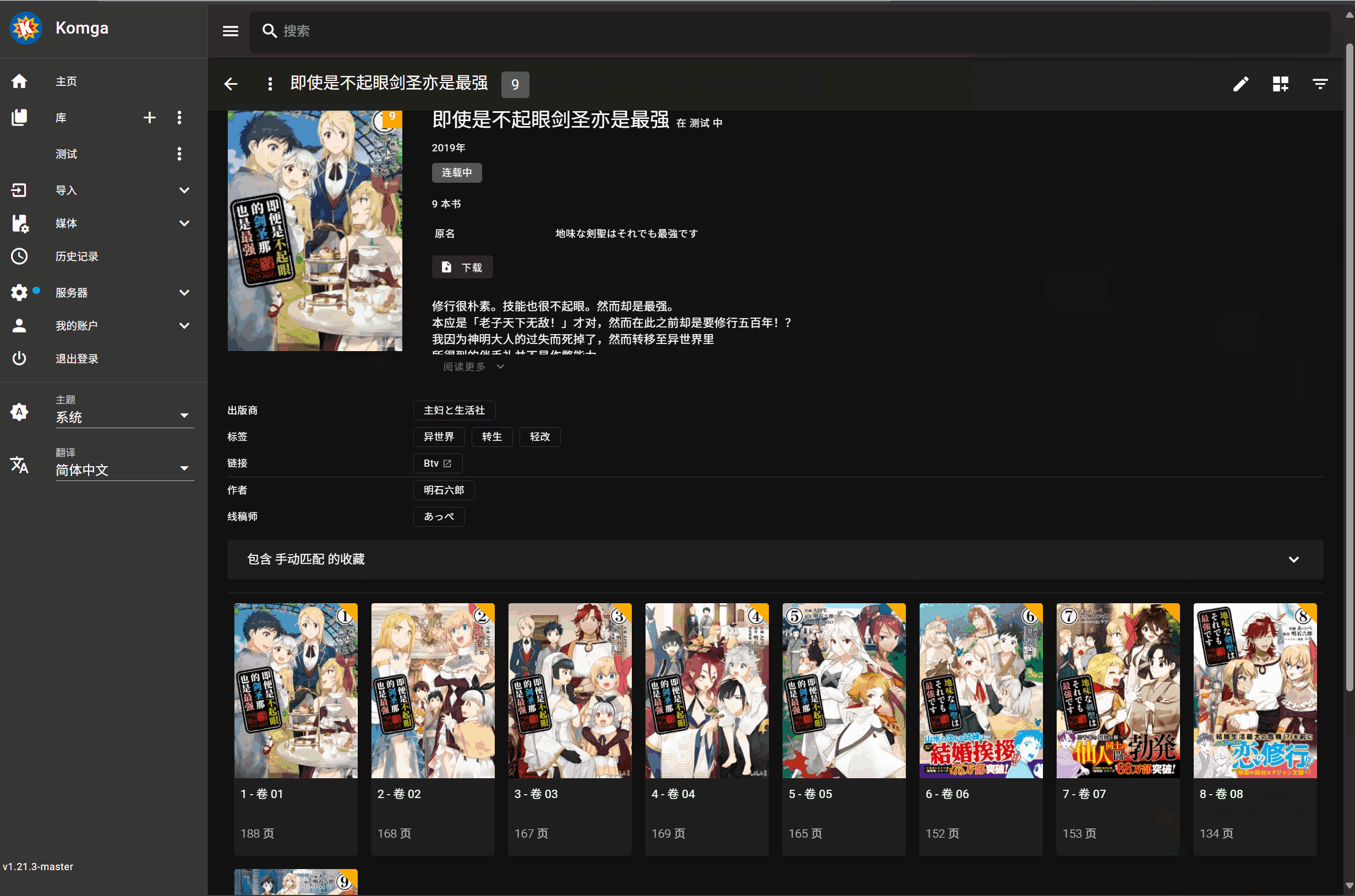
演示:
最终结果:
手动匹配操作
- 点击书籍封面上的刮削按钮
- 选择刮削源(如 Bangumi)
- 选择要刮削的书名
- 点击匹配项,开始刮削(无需刷新,Komga 会自动更新展示)
元数据更新时对于单行本数据只有当从文件名中提取的单行本序号和 bangumi 上对应漫画的单行本序号一致时才会更新
演示:
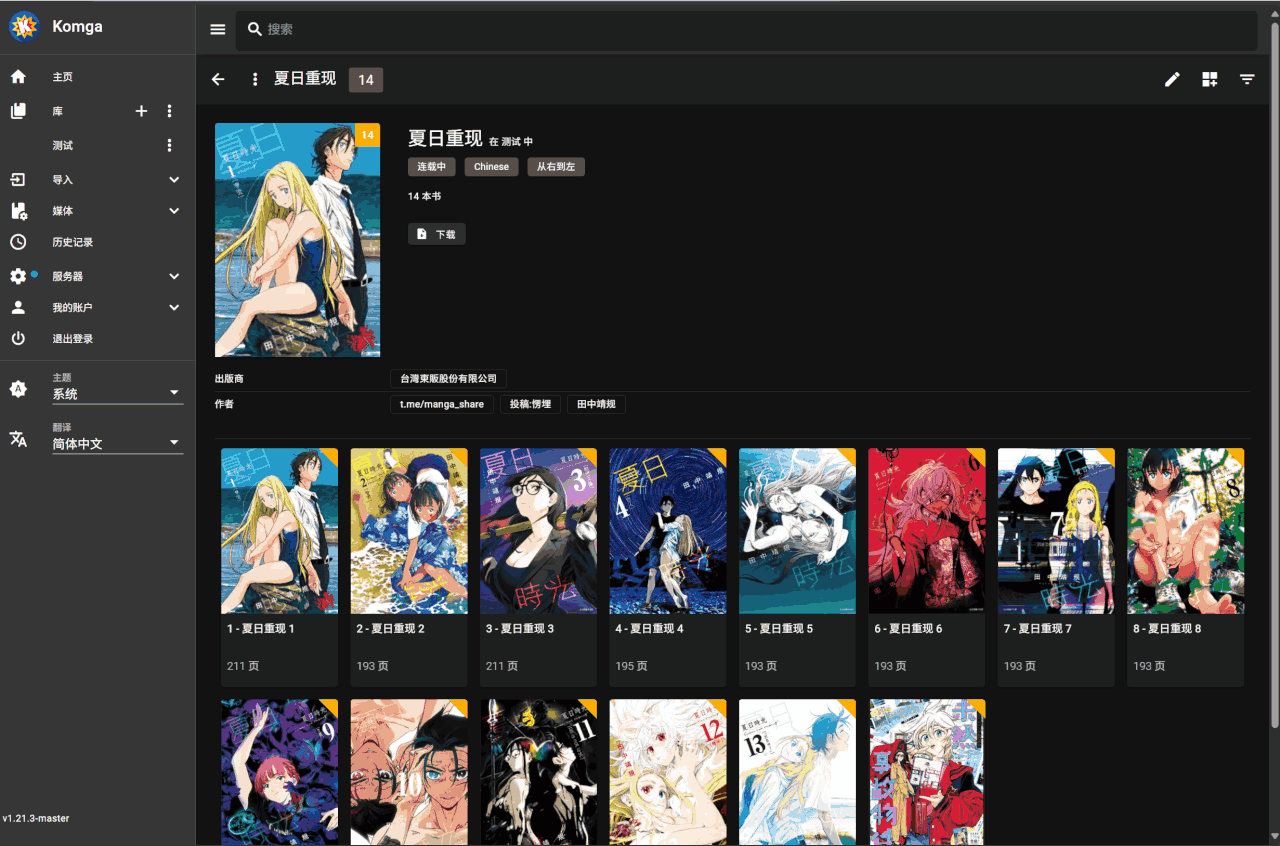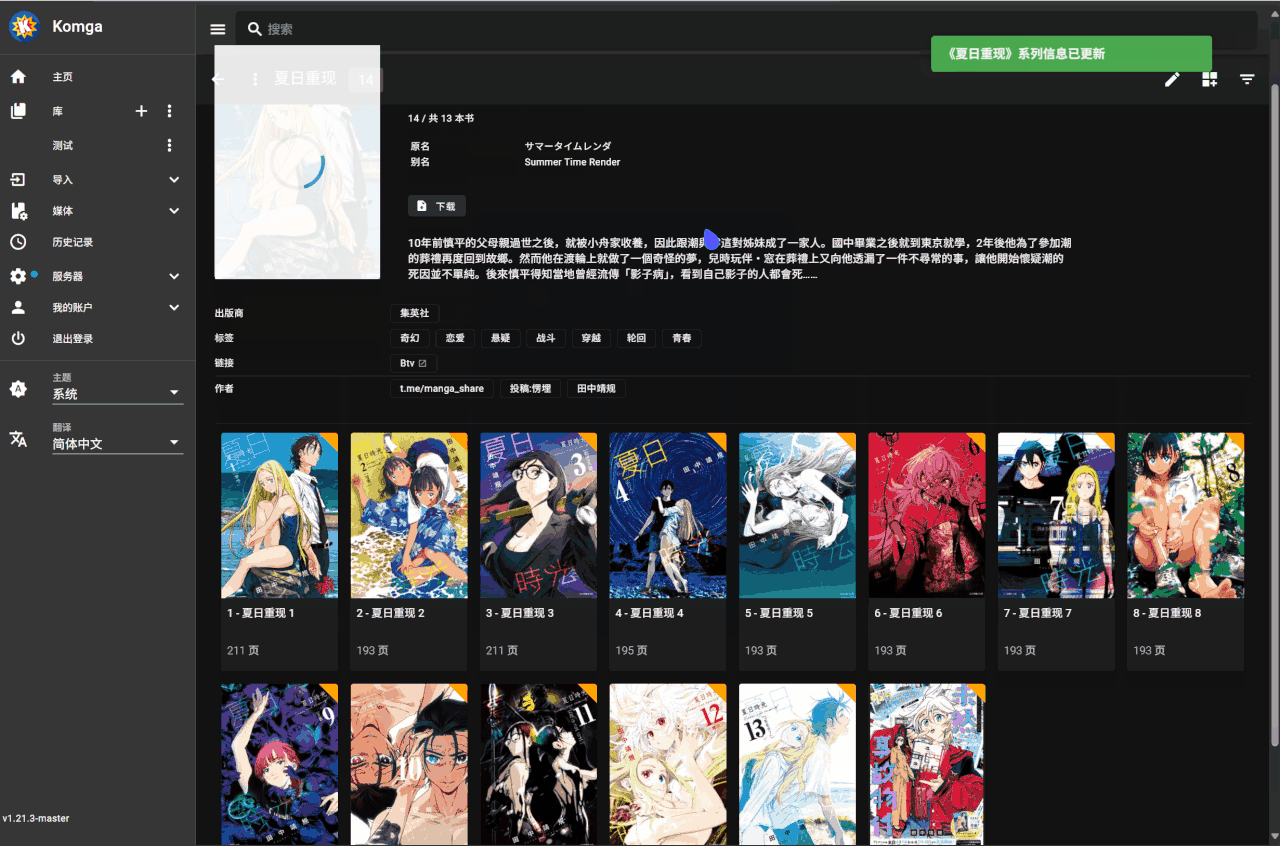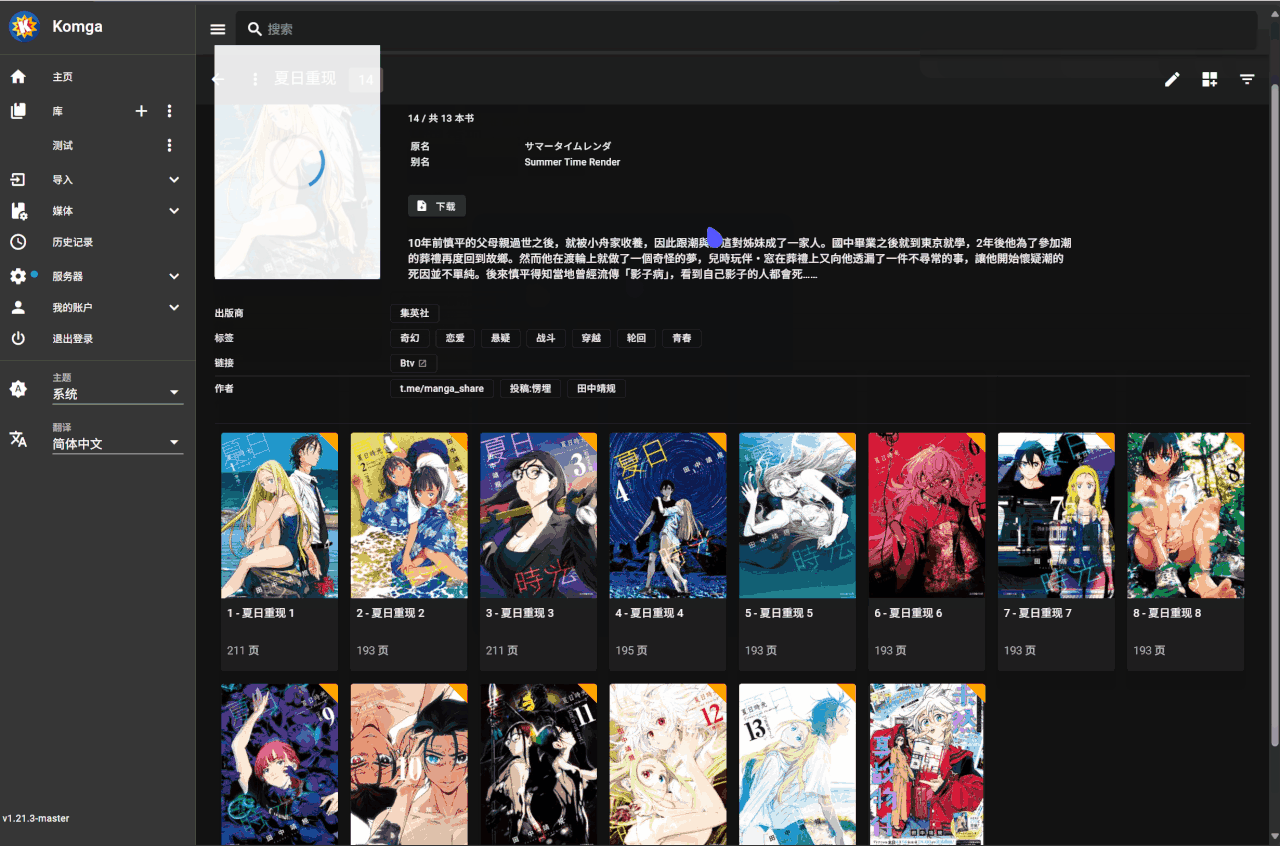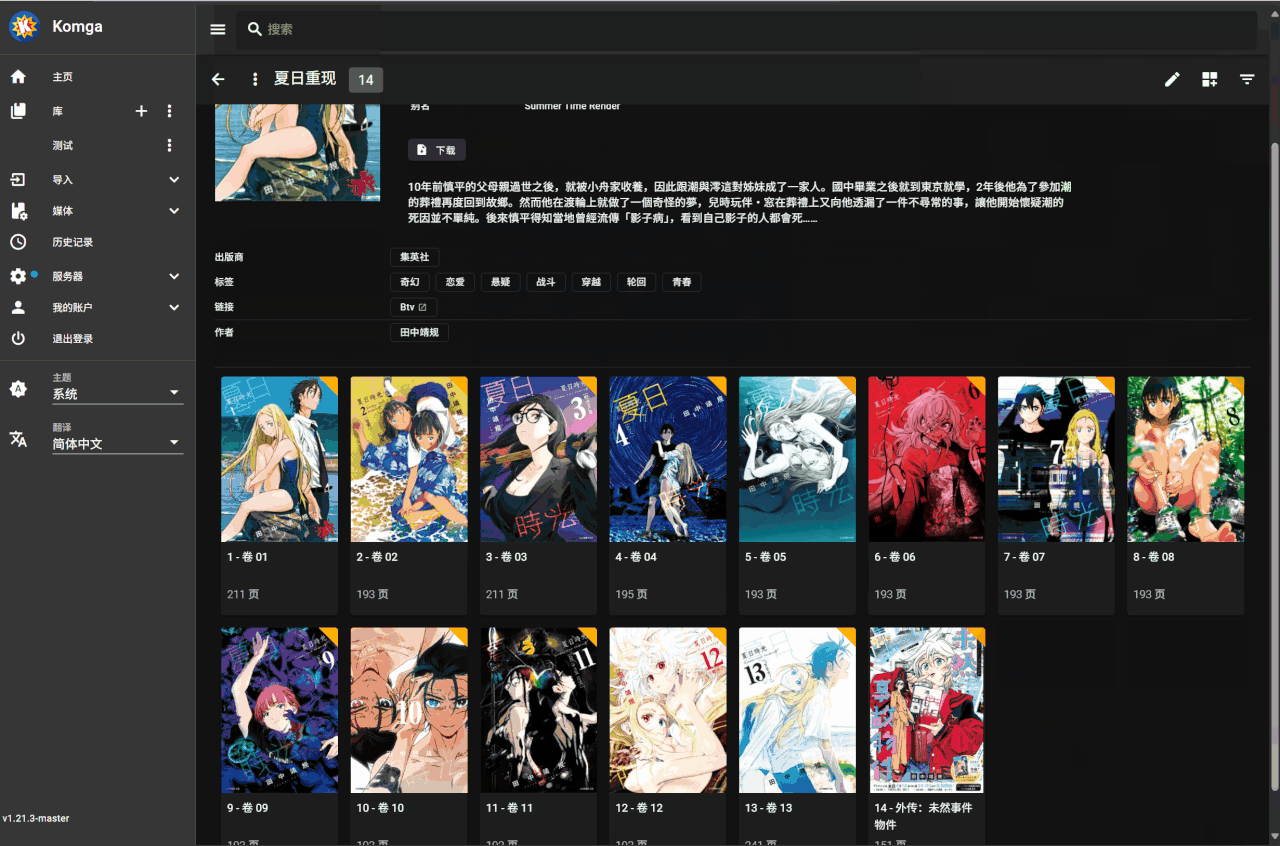
无法正确获取书籍名时的操作
当脚本无法从文件名中正确获取书籍名时,有以下三种处理方式
-
手动输入正确的关键字进行搜索
-
直接修改 Komga 上的漫画标题为正确名称后再次执行手动搜索
-
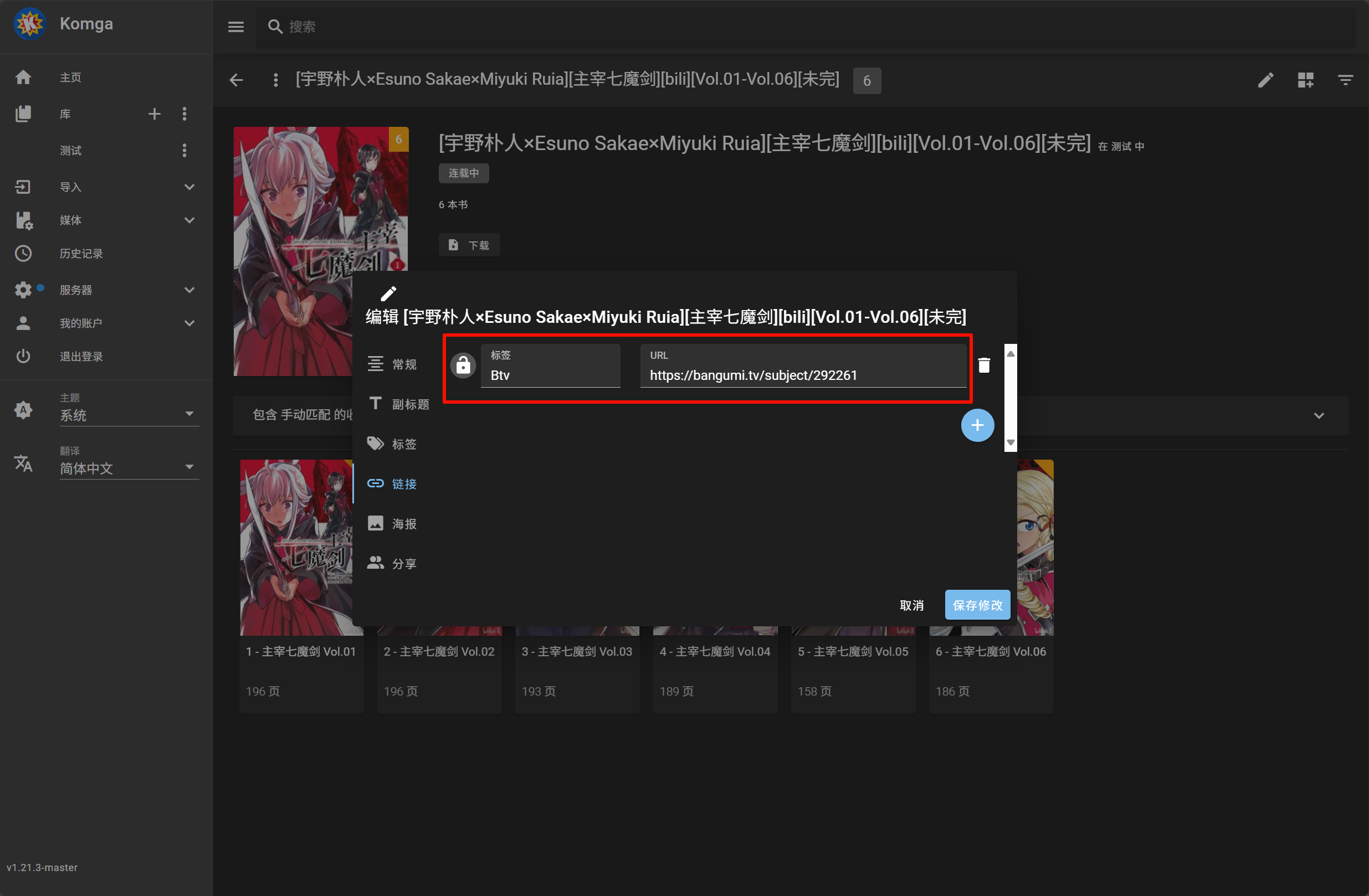
可以手动到 bangumi 网站检索到正确书籍后,复制其 URL,编辑漫画的链接一栏添加对应的项即可比如
'Btv': 'https://xxxx',保存后再更新漫画选择该源即可
前两种操作比较好理解,下面演示下第三种操作:
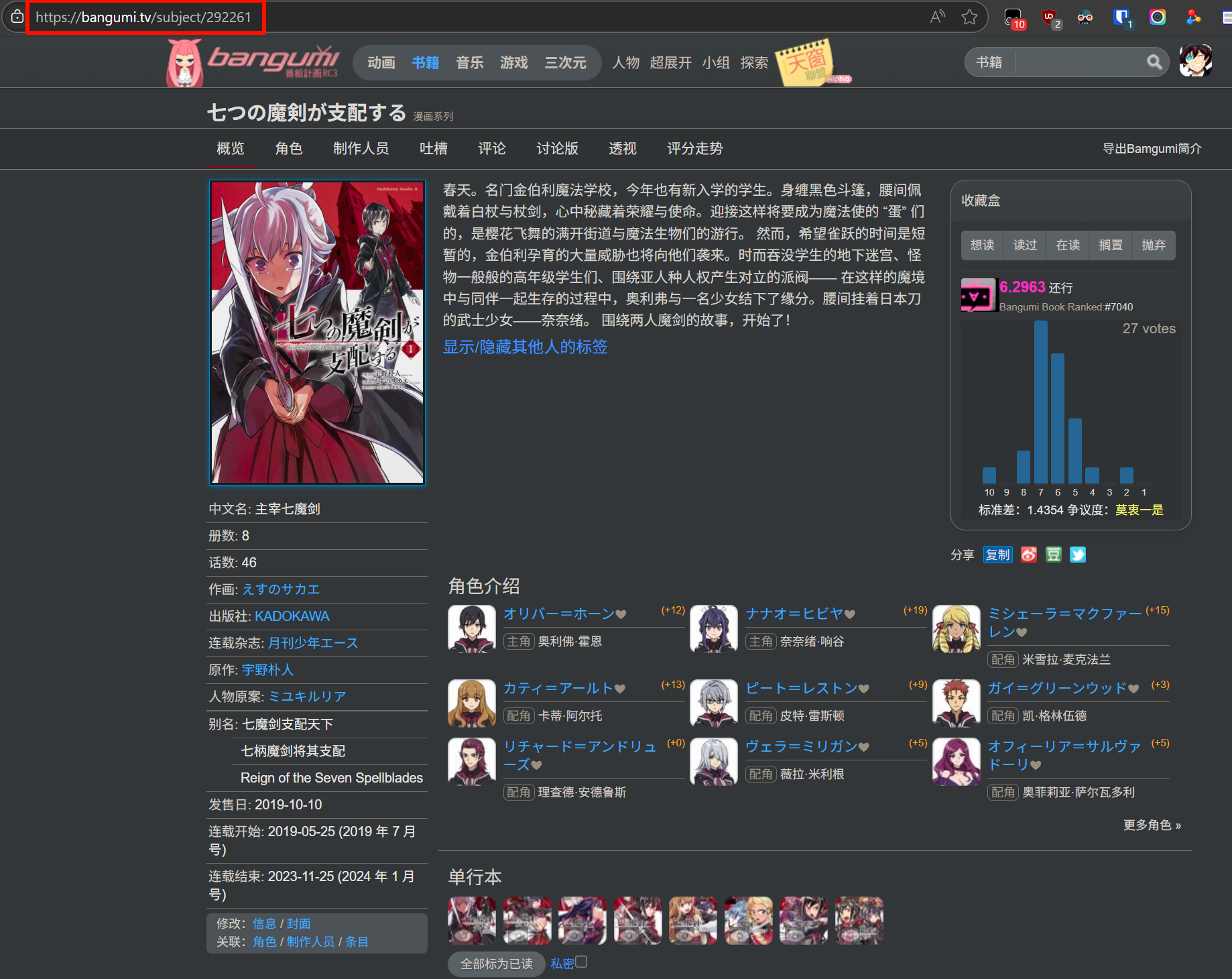
-
在 bangumi 网站搜索并找到漫画条目,复制其 URL
-
编辑 Komga 上对应漫画的链接一栏添加对应的
Btv项并保存
-
点击书籍封面上的刮削按钮进行元数据匹配执行刮削操作